
3 June, 2026 - Last week in TI
- Rahul Subramaniam
- Releases
- June 3, 2026
Legal Intake: User-Controlled Notifications, Attorney Performance Dashboard & Workflow Redesign
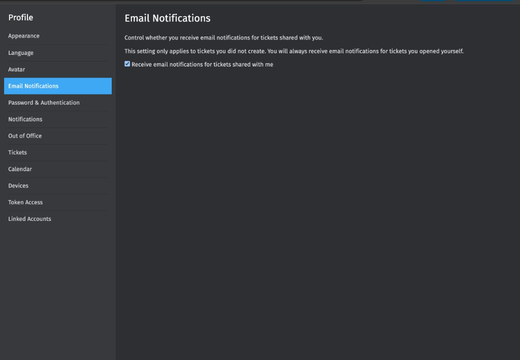
Legal Intake empowers users to control email notifications on shared tickets, provides legal admins with attorney performance dashboards, fixes critical submission and notification bugs, and initiates major workflow redesign for NSNS vendor intake.
- User-Controlled Email Notifications – Customers can now enable or disable email notifications for tickets shared with them, giving users full control over their inbox without losing access to tickets.
- Attorney Performance Dashboard – Legal admins now have visibility into response times, identifying when attorneys are not responding for >72 hours and enabling proactive follow-up.
- Critical Bug Fixes – Fixed ticket creation without document uploads, resolved summary approval blocking during legal submission, and corrected individual attorney email notification delivery failure.
- Workflow Redesign – Did a meeting with Lance and Julian to completely redesign pre-ticket submission workflow and integrate Claude tool for automated redline generation in NSNS vendor intake system.
EduPaid v2.30.0: State Expansion, ESA Eligibility & In-App Support
June 3, 2026 (v2.30.0) expands live coverage to Arkansas and Wyoming (product approval pending), onboards provider 100For100, sends volunteer outreach to ESA-state parents, and ships a guided ESA Opportunity modal plus floating Help support in the parent portal.
- States & operations: EduPaid is now approved in Arkansas and Wyoming, with product approval still pending in those states. New provider 100For100 has completed onboarding and has a meeting scheduled. Volunteer outreach emails went out to support ESA-state parents.
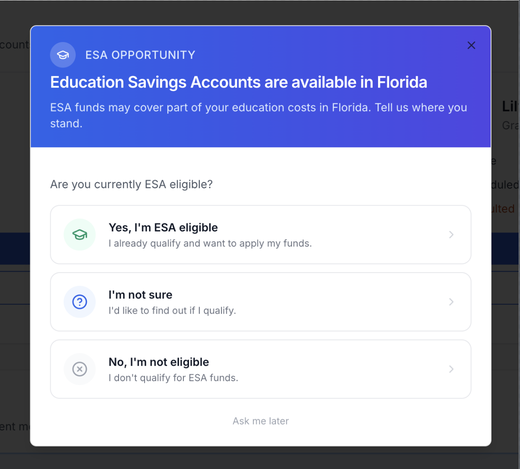
- Parent portal — ESA eligibility modal: Parents in ESA-supported states see a guided ESA Opportunity prompt on the dashboard when it is time to confirm eligibility—three paths (eligible, not sure, not eligible) route to the right checkout flow, your state’s external eligibility site, or contact details. Eligible families with multiple learners pick which student to start the application for; states with a documented ESA flow go to step-by-step checkout, others see the generic information page with the right contacts.
- Parent portal — in-app customer support: A floating Help button on most student-portal pages offers ESA-focused FAQs (adding funds, balance updates, state eligibility) and a free-text Ask anything path to the EduPaid team without leaving the app. The widget hides during purchase and ESA checkout so it does not block payment.
EduLLM SAT (Reading and Writing)
EduLLM SAT-RW broke through last week’s ~90% plateau this week with dataset quality fixes, ranker experimentation, and multi-grade expansion. The supervised fine-tuning approach with Llama 70B reached 93% raw pass rate on PSAT 8/9 and 96% with a ranker. Agentic generation maintained 100% pass rate on IB even after a 7x dataset multiplier was applied for low-standard-count grades.
- Agentic Generation at 100% – The agentic generator maintained 100% pass rate on InceptBench even after a 7x dataset multiplier was applied for grades with fewer than 200 standards.
- Dataset Quality Fix & Per-Standard Improvement – Identified and fixed a round-robin answer key bug across all training examples, along with per-standard stimulus issues. The fixed dataset improved raw PSAT 8/9 pass rate from ~90% to 93%, with further gains to 96% using a ranker on top.
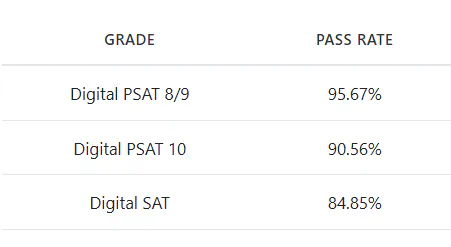
- Multi-Grade Expansion – Extended Llama-3.3-70B fine-tuning to PSAT 10 and SAT curricula for the first time, with 500 samples per tuple. Achieved 90.56% on PSAT 10 and 84.85% on SAT (raw, no ranker).
Athena Applets: Grade 5 Expansion & Iteration Activity
3 new Grade 5 lessons generated this week. No customer review approvals occurred during this period. The autonomous agent completed 8 fixing sessions with a 98% success rate, resolving 204 out of 209 issues.
- Production output – 3 new lessons generated and entered review queue (CCSS.MATH.CONTENT.5.NBT.A.2+2, CCSS.MATH.CONTENT.5.NBT.A.2+3, CCSS.MATH.CONTENT.5.NBT.A.2+5, all Grade 5). 67 iterations produced across 35 unique lessons. No customer approvals this week.
- Autonomous agent performance – 98% success rate across 8 fixing sessions (204 issues resolved, 5 failures), with an average of 6.9 feedback rounds per lesson.
- Efficient iteration cycle – 18 total iterations completed in the past 7 days (all feedback rounds, 0 approvals) with an average of 4.8 comments per lesson (87 total comments).
- Multi-grade coverage – Current review queue: 130 lessons ready for validation (Grade 3: 22, Grade 3 Supporting: 38, Grade 4: 4, Grade 6: 60, Grade 7: 3, Grade 5 TEKS: 1, Grade 6 TEKS: 2).
- Review time insights – Average review time of 7.8 minutes per iteration (total 139.9 minutes).
- Complete lesson catalog – See the full list of all uploaded lessons across grades in this lesson catalog with direct links to each lesson.
EduLLM Science: SFT at 98%, Two-Pass Quality Approach
This week the SFT pipeline reached ~98% pass rate on multi-candidate benchmarks, but stalled on single-pass quality. To break through, we introduced a two-pass approach — a verifier model performs a second quality-enforcement pass on each generated question. Early results are promising and we are iterating to close the remaining gap to our quality targets.
- SFT progress – Reached ~98% on multi-candidate benchmarks; single-pass quality is the current bottleneck.
- Two-pass verifier – A second verification pass is being added to enforce question quality before output, with early results already showing improvement.
EduLLM Social Studies: 97.3% Single-Candidate on IB v2.5.11, Agentic Recovery Underway
EduLLM Social Studies reached 97.3% on single-candidate generation on InceptBench v2.5.11. After incorporating academic feedback, the agentic generator regressed in parts of the curriculum, but Grade 7 has recovered to 99%.
- Single-candidate milestone – Achieved 97.3% on single-candidate evaluation on IB v2.5.11.
- Post-feedback regression – Following academic feedback integration, the agentic generator showed a temporary regression in overall performance.
- Grade 7 recovery – Grade 7 is back at 99%, validating the current iteration direction as we restore the remaining grades.
BrainTrust
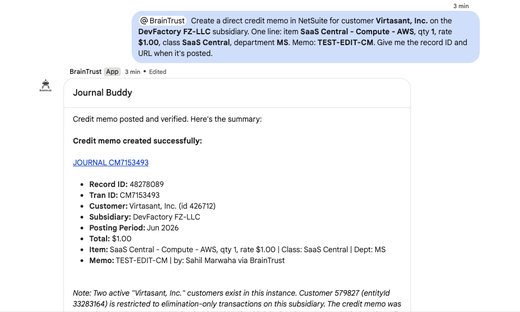
The BrainTrust Finance Agent can now create and edit a broader range of financial records, giving teams more coverage directly from the agent without switching tools.
- Expanded Posting Creation – The agent now supports creating postings for Direct Invoices, Credit Memos, Deposits, and Payments, in addition to existing types.
- Record Editing – Users can now edit most of these record types directly through the agent, streamlining corrections and updates.
- Coming Soon – Modification support for Deposits and JEs is currently in development. Work is also underway to enable creation of Billing Accounts, Subscriptions, Invoices, and CMs via Subscription, and to improve Balance Sheet agent performance.
Alpha Coach Analysis Platform: Session History, Auto-Update & Deeper Coaching
Coaches can now replay any past Alphi session, the desktop app updates itself automatically, and Alphi’s coaching is deeper — it catches prerequisite gaps and never hands over the answer.
- My Alphi — Session History — Coaches can now open any past Alphi session and see the full transcript with screenshots captured at each coaching moment. Full history, always there.
- Desktop Auto-Update — The desktop app now updates itself silently in the background. No more downloading and reinstalling when a new version ships.
- Alphi — Deeper Coaching — Alphi now detects when a student is stuck because of a missing foundational skill, pauses to teach that gap, checks understanding, then returns to the original work. It also never hands over the answer — even after repeated wrong attempts, it redirects the student to self-check instead.
- Faster App — Coach and session pages now load 2–3 seconds faster across the board.
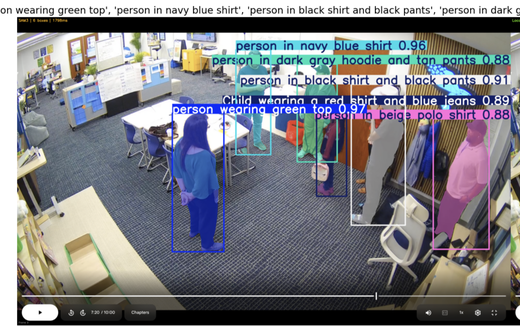
Marauders Map: MFIPS False-Positive Deep Dive — Multi-Signal Experiments
This week we ran a series of targeted experiments aimed at reducing false-positive identity matches in our MFIPS (Multi-Factor Identity Persistence) pipeline. The core investigation focuses on apparel-based tracking with separated torso & leg regions, plus exploratory probes into gait/skeleton and gender signals as supplementary identity guards.
- Apparel Tracker — Torso & Legs Separation via SAM3 — Isolates torso vs. legs using SAM3 segmentation masks and extracts independent HS colour histograms for each zone. By treating upper and lower body as separate appearance channels, partial clothing changes (e.g. removing a jacket) degrade matching less than a single full-body descriptor. Tested on the Heron false-positive clips at 10 fps, comparing fragmentation and ID-switch rates against the combined-histogram baseline.
- Skeleton Anthropometric Embedding — Gait & Body Proportions — Derives camera-angle-invariant body-proportion ratios (shoulder width / body height, torso / leg ratio, arm span / height) from existing RTMPose keypoints and encodes them as a low-dimensional embedding. These ratios remain stable per-person across sessions — providing a soft biometric signal that persists when face crops fail due to blur, occlusion, or overhead angles.
- Gender & Age Probe — Cross-Track Consistency Guards — Benchmarked InsightFace + DeepFace against MiVOLO v2 (ViT-based) for gender/age estimation on SAM3 body crops. If gender consistency exceeds 80% across tracks, two MFIPS guards become viable: reject face-rec matches where detected gender contradicts the gallery identity, and block gallery pollution from mismatched-gender assignments — preventing obvious cross-gender false merges.
EduLLM-ELA: Grade-6 Question Generation — gemma-4-31b at ~98% (N=3), gemini-3.5-flash at 99.2%
We benchmarked generators for Grade-6 ELA question generation on InceptBench: gemini-3.5-flash reaches 99.2% at N=3, and the open gemma-4-31b reaches ~98% at N=3 (~96% single-pass) at a fraction of the cost. We’re now fine-tuning gemma to close the gap.
- gemini-3.5-flash — 99.2% at N=3 — Our strongest Grade-6 ELA generator: 3 candidates ranked, ~3.3 cents per question.
- gemma-4-31b — ~96% at N=1, ~98% at N=3 — The open model: a single tuned-prompt pass scores ~96%; a best-of-3 ranked pipeline reaches ~98%, at only ~1–3 cents per question. N=5 did not beat N=3 — the quality ceiling is the ranker, not more sampling, making N=3 the cost-optimal point.
- Template-driven generation across all Grade-6 Language strands — Per-cell templates (standard × question type × difficulty) drive the generator, with active rollout across Writing, Reading, Speaking, and Language Conventions.
- Fine-tuning underway — We’re now running supervised fine-tuning (SFT) on gemma-4-31b to close the gap to gemini-3.5-flash and push pass rates higher.

EduLLM SAT Math: Strong Quality on Image-Based Questions Across All Digital SAT Grades
SAT Math now posts strong quality on image-based questions across all three Digital SAT grades, with pass rates of 97.41% (PSAT 8/9), 94.12% (PSAT/NMSQT & PSAT 10), and 94.74% (Digital SAT). Work is underway to push every grade band to a sustained 99% pass rate.
- Digital PSAT 8/9 – On 270 evaluated image-based items: 99.44% aggregate score, 97.41% pass rate, and 83.51% variety score.
- Digital PSAT/NMSQT & PSAT 10 – On 51 evaluated image-based items: 98.38% aggregate score, 94.12% pass rate, and 87.55% variety score.
- Digital SAT – On 228 evaluated image-based items: 98.96% aggregate score, 94.74% pass rate, and 83.68% variety score.
- Quality roadmap – Continued improvements are focused on raising image-question quality further and moving all grade bands toward a sustained 99%+ pass rate.