
27 May, 2026 - Last week in TI
- Rahul Subramaniam
- Releases
- May 27, 2026
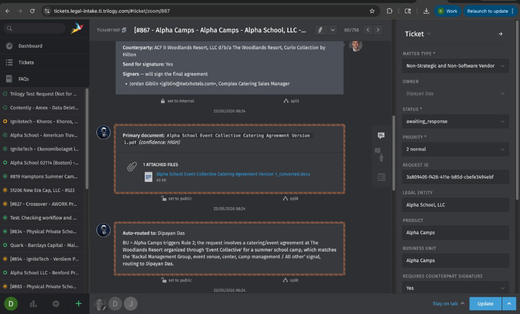
Legal Intake: Intelligent Document Routing, Auto-Assignment & Invoice Attribution
Legal Intake automates primary document detection and conversion, routes 46% of tickets to attorneys automatically, ensures accurate invoice attribution with immutable references, and streamlines approver workflows—eliminating manual steps and preventing billing errors.
- Automatic Primary Document Detection & Conversion – System identifies the primary document and auto-converts PDF to DOCX, making manual intervention redundant.
- Automatic Attorney Assignment – Non-Strategic and Non-Software Vendor intake system now auto-routes to the appropriate attorney based on historical data.
- Immutable Invoice Reference Field – Added a dedicated invoice reference field that preserves original request number, BU and Product.
- Automatic Approver Sharing – System automatically shares tickets with business approvers, eliminating manual sharing step for ticket creators.
- Fixed Customer Blockers, Enhanced UX & Relative Time – Fixed blocking issue when customers navigated back after summary generation, enabled document attachment while editing, and added relative timestamps in AI summaries for better context.
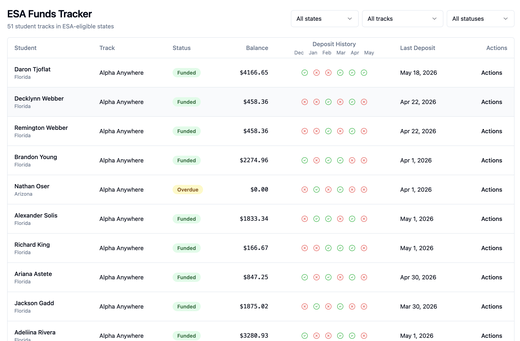
EduPaid v2.29.0: ESA Funds Tracker & Mastery Tokens
May 27, 2026 (v2.29.0) gives ESA-eligible-state providers an ESA Funds Tracker for wallet balance, funded vs overdue status, six-month deposit history, filtering, and parent refill reminders. TimeBack mastery completions surface on provider student profiles and in a dedicated admin Mastery Tokens workflow so payout status stays in one place.
- Provider portal — ESA Funds Tracker: In ESA-eligible states, view each student’s ESA funding health in one place—current wallet balance, funded vs overdue, and a six-month deposit history with green/red indicators per month so you spot who needs a refill before billing stalls. Filter by state, learning track, or status (including overdue enrollments); from row actions, send refill reminders to parents for a specific student and track.
- Provider portal — Mastery Tokens on student profiles: When learners complete mastery assessments through TimeBack, results appear on the student detail page under Mastery Tokens with score, date, and Paid or Pending badges; open any student and use the tab to review that learner’s completions without guessing disbursement state.
- Admin portal — Mastery Tokens management: A sidebar Mastery Tokens page lists completions across the platform—student, provider, learning track, score, completion date—with filters for student ID, provider, or learning track. Mark rows paid when disbursement completes; the same data appears on the student detail tab for family support workflows, reducing spreadsheet reconciliation.
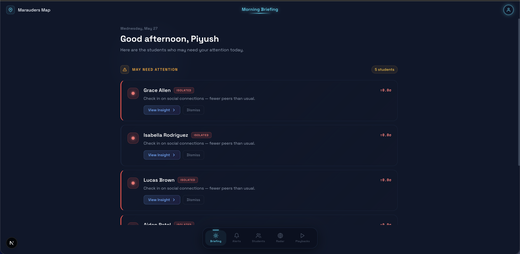
Marauders Map: Apparel-Aware Tracking & Guides Dashboard
Two major capabilities this week: a new apparel-aware tracker that uses clothing colour to dramatically reduce identity switches during live tracking, and a full Guide Dashboard giving teachers a spatial-intelligence command centre for student wellbeing.
- Apparel-Aware Tracking — A new greedy tracker uses SAM3 masks to isolate each person, then matches them frame-to-frame via a 3-factor cost: IoU + centroid distance + clothing colour (HS histogram, no brightness). Result: 31% less fragmentation than Hungarian and 49% less than BoT-SORT on the Alpha NY classroom video — far fewer identity switches when students cross paths or occlude each other.
- Guides Dashboard — A dashboard for school guides with four views: Morning Briefing ranks priority students by spatial z-score with drill-down and talking points; Risk Radar fuses spatial signals with LMS mastery into a composite urgency score with weekly trend charts; Alerts streams real-time absence, wellness-check, and geofence notifications; My Students shows a searchable roster with presence timelines, interaction logs, and co-location metrics — full spatial context without raw video.

EduLLM SAT (Reading and Writing)
EduLLM SAT-RW achieved significant performance improvements this week through dataset multiplier optimization and SFT experimentation. The agentic generator maintained 99%+ pass rates despite a 7x dataset expansion for low-standard-count grades, while our supervised fine-tuning approach with Llama 70B reached 91.77% on PSAT 8/9. A promising N=3 ranker experiment pushed performance to 94.8%, with detailed cost analysis showing competitive inference pricing.
- Dataset Multiplier Implementation – Applied 7x multiplier for SAT-RW grades with <200 standards to increase dataset size while maintaining the existing agentic generator’s 99%+ pass rate performance.
- Base SFT Performance with Llama 70B – Reached maximum of 91.77% pass rate for PSAT 8/9 on InceptBench using supervised fine-tuning approach with Llama 70B.
- N=3 Ranker Experiment – Experimented with a 3-candidate ranker on top of the SFT model, achieving 94.8% pass rate with cost calculations detailed in the attached pricing comparison.
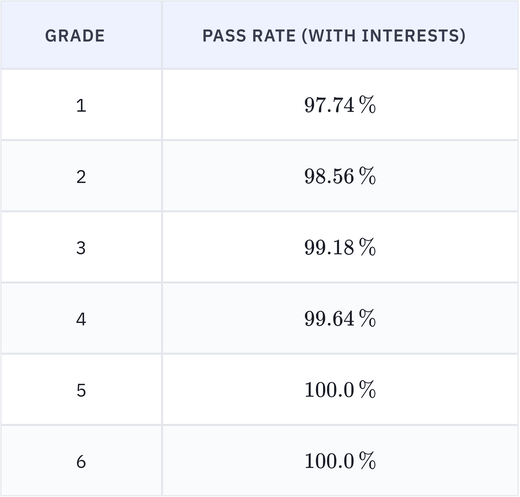
EduLLM Math: 99% on grades 3-6 for interests on Agentic model
Agentic model has hit 99s on grades 3-6 for interests.
- 99% pass rate: Pass rate for Math Grades 3-6 with interests has improved to 99%+.
- SFT: SFT model for grade 4 hit its best at 96% pass rate, efforts to improve that by mixing the agentic model with the SFT model are ongoing.
InceptBench: Smarter Evaluator, Live Catalog & New Question Types
A sharper evaluator that catches more bad questions, a homepage that now shows the real benchmark catalog (170 sets, 9 subjects), richer curriculum context inside every run, and end-to-end support for SAT-style numeric grid-in questions.
- Smarter evaluator — New checks catch question issues the evaluator used to miss: misleading distractors, answers given away by images or geography, and explanations that claim something is in the text when it isn’t.
- Live benchmark catalog on the landing page — The homepage now reads counts directly from the latest snapshot (170 benchmark sets across 9 subjects) instead of hardcoded numbers, so it always matches what’s actually available.
- Richer curriculum context in every run — Each request in Run Detail now shows lesson name, key concepts, full standard ancestry (Subject › Course › Domain › Cluster), and per-level Easy/Medium/Hard difficulty definitions, pulled live from the Curriculum API.
- Auto-repeat for small datasets — When a question run has too few items, the system automatically repeats each one enough times to reach ~200 samples, so results stay statistically stable without any manual setup.
- 5 certifications from the Academics team — InceptBench earned 5 formal certifications from the Academics team this week, confirming evaluator alignment with curriculum standards.
- Generator issues resolved in under 24h — Every issue raised by the Generators team this week was fixed and shipped to production within 24 hours.
- SPR (Student Produced Response) end-to-end — Added support for SAT-style numeric grid-in answers across the renderer and evaluator, with strict input rules (no mixed numbers, length caps, tolerances) and deterministic scoring on the numeric answer. Also fixed LaTeX rendering in articles and made stimulus passages show up on more question types.
Athena Applets: New Lesson Generation & Agent Improvements
1 new lesson generated this week (Grade 3 Supporting). No customer review activity occurred during this period. The autonomous agent completed 8 fixing sessions with a 98% success rate, resolving 120 out of 122 issues.
- Production output – 1 new lesson generated and entered review queue (TEKS.MATH.CONTENT.3.5.C+1, Grade 3 Supporting). 21 iterations produced across 19 unique lessons. No customer reviews or approvals this week.
- Autonomous agent performance – 98% success rate across 8 fixing sessions (120 issues resolved, 2 failures), with an average of 4.3 feedback rounds per session.
- Review queue – 138 lessons ready for validation (Grade 3: 27, Grade 3 Supporting: 40, Grade 4: 4, Grade 6: 60, Grade 7: 4, Grade 5 TEKS: 1, Grade 6 TEKS: 2).
- Complete lesson catalog – See the full list of all uploaded lessons across grades in this lesson catalog with direct links to each lesson.
InceptBench v2.6.4: SPR Type, Evaluator Hardening & Schema-Agnostic Scoring
InceptBench v2.6.4 launched the Student Produced Response question type, hardened the evaluator with SAT R&W curriculum-alignment rules and meta-guards against self-rationalization, switched scoring to schema-agnostic question-quality detection, and improved benchmark observability with live curriculum data and auto-repeated small datasets.
- Student Produced Response (SPR) question type — Added SPR across the evaluation pipeline and content renderers, supporting numeric and algebraic responses with dedicated rendering, scoring logic, and LaTeX equation support. Stimulus now renders as markdown above the question body.
- Evaluator guard and prompt hardening — Rolled out multiple prompt-level fixes: rhetorical-synthesis rules and inference-explanation verifiability for SAT R&W, a SIG-9 audit for technology-use curriculum mismatches, geographic-telegraphing detection for MCQ distractors, and meta-guards that prevent the evaluator from self-rationalizing its own leaks. Also tightened visual-depicts-answer rules for science diagrams and topically misaligned distractor detection.
- Schema-agnostic scoring & DBQ alignment — The evaluator now flags only on question quality regardless of schema format, factual-audit skips correctly propagate into overall reasoning instead of being silently dropped, and DBQ curriculum alignment was strengthened with golden regression coverage.
- Benchmark platform & data reliability — The landing page now shows actual benchmark set and subject counts, RunDetail live-fetches rich Incept Curriculum data, and small question datasets are auto-repeated to reach at least 200 samples for statistical reliability. QTI compliance sampling now sources seeds directly from the curriculum API.
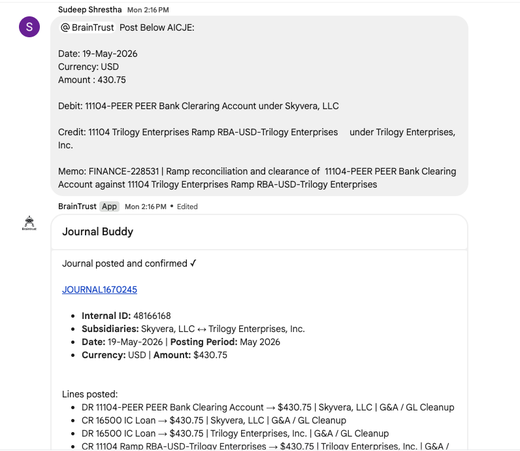
BrainTrust: Finance Agent, Hermes Ops Framework & Docate Screenshot Automation
BrainTrust shipped a new Finance Agent for NetSuite journal and AICJE posting, kicked off the Hermes multi-agent ops framework for unified project management, and upgraded Docate with autonomous screenshot capture via targeted Playwright scripts.
- Finance Agent for NetSuite – A new agent built for the finance team automates posting of journals and AICJEs directly to NetSuite. Already in active use by the finance team, with plans to expand its scope further.
- Hermes Agents Framework – A new multi-agent setup is being developed to serve as a single interface managing all aspects of BrainTrust operations and project delivery.
- Docate: Autonomous Screenshot Capture – Docate’s agent can now autonomously capture screenshots by writing targeted Playwright scripts, significantly reducing the need for human involvement in the documentation workflow.

EduLLM SAT Math: Strong Benchmark Scores & SPR Question Support
SAT Math posts strong scores across all three Digital SAT grades on text-based questions (substandards requiring images are excluded). Only failure reason for questions was difficulty alignment — a curriculum update is planned to fix this. Added SPR question type support this week.
- Benchmark scores (text-based questions, image substandards excluded) – Digital PSAT 8/9: 98.71% pass rate (99.71% aggregate). Digital PSAT/NMSQT and PSAT 10: 94.05% pass (98.77% aggregate). Digital SAT: 98.47% pass (99.62% aggregate).
- SPR question support – Added support for generating Student-Produced Response (SPR) questions.
- Failure analysis – All failing questions failed due to difficulty alignment; no other failure categories. Curriculum update in progress to resolve this.
- Next steps – Add image generation support and update the curriculum to fix difficulty alignment issues.
Alpha Coach Analysis Platform: Alphi Accuracy, Guide Insights & Faster Analysis
Alphi now grades answers from what the learning platform shows — not what students say out loud — guide feedback emails are sharper and more actionable, and session analysis runs 3× faster.
- Alphi — Platform-Verified Answers — Alphi now grades student answers by watching the learning platform itself — green checks, score changes, “Correct!” — instead of trusting what the student says out loud, eliminating false praise on wrong answers.
- Guide Feedback Emails — Coaching feedback emails to guides now open with the key takeaways, concrete next steps for the student, and specific moments from the session that triggered each recommendation.
- 3× Faster Session Analysis — Sessions are now processed in parallel, so coaches see results sooner after each call.
EduLLM-ELA: Self-evaluation training flips on smaller models — 14B gains what 32B couldn’t
Benchmark results on 621 Grade-6 ELA questions reveal a clean scale-dependent split: joint self-evaluation training hurts the 32B model but meaningfully improves the 14B model.
- 32B has hit its ceiling on this benchmark. The fine-tuned 32B baseline scores 88.6%. Adding inference-time rewriting — where the model critiques and rewrites its own output — moved the needle by just +0.1pp (88.7%), with zero broken outputs. No real lift; the model is already near-optimal for this task.
- Joint self-evaluation training scales in reverse. Training the 32B model to simultaneously generate and grade its own work regressed accuracy by 3.4pp (85.2%, 5 broken outputs). The same technique on the 14B model improved accuracy by +1.6pp (76.5% → 78.1%) and cut broken outputs from 79 to 2.
- The finding: self-evaluation training adds value specifically where there’s headroom — the 14B model had it, the 32B didn’t. Next focus is understanding why the technique destabilises the larger model.