
20 May, 2026 - Last week in TI
- Rahul Subramaniam
- Releases
- May 20, 2026
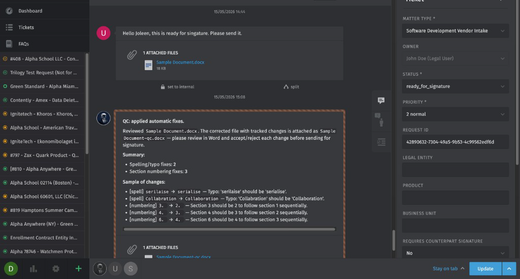
Legal Intake: QC Agent, Document Workflow Automation & Analytics Dashboard
Legal Intake automates document quality control, streamlines PDF/DOCX workflows with redlining, enables programmatic request creation via API, fixes interactive review reliability, and provides real-time performance analytics through Grafana dashboards.
- QC Agent – Automated quality control fixes formatting issues, section numbering, and spelling mistakes before signature, eliminating manual review cycles and saving signers’ time.
- PDF↔DOCX Conversion & Redlining – Easy document format conversion and redlining capabilities eliminate the need to download, use third-party software like Adobe, and re-upload—saving legal admin time per request.
- API for Request Creation – Programmatic request creation now available via REST API, enabling integration with external systems and automated intake workflows.
- Grafana Performance Dashboard – Real-time analytics tracking negotiation lag, signature lag, ticket assignment lag, and ticket resolution lag—providing visibility into bottlenecks and performance.
- Interactive Review Reliability Fix – Fixed ‘Assistant is analyzing your response’ forever loop through stale thread-run cleanup scheduler and webhook retry handling, ensuring reviews never get stuck.
InceptBench v2.6.0: Resumable Runs, Sharper Audits & Monorepo Move
InceptBench 2.6.0 makes long evaluations resumable, tightens audit and consensus correctness, kills a class of stimulus/prompt false positives, and folds the inceptbench.com website into the main monorepo.
-
Resumable & Faster Evaluations — New
--resumeflag on theevaluateCLI picks up interrupted runs where they left off (#18), andcurriculum_datacan now be passed directly to the evaluator to bypass the API lookup on hot paths (#135). -
Sharper Audits & Consensus — Factual-accuracy audit failures now propagate into overall reasoning instead of being silently dropped (#286), the decomposer fails loudly on errors rather than flattening (#192), and
_merge_binary_metricsis now a deterministic majority pick (#403). -
Prompt & Stimulus Quality Fixes — Eliminated the narrative “is looking at” stimulus false positive (#469), flagged opposite/negation distractors as too obvious (#460), added a fill-in-the-blank specificity check (#465), and tightened FILL_IN
accepted_answersmulti-set handling and keyword matching (#390, #430). -
Image & Vision Reliability — Fixed Gemini 400s and
interest_relevancefalse INFERIOR ratings on SVG/image questions, preventedmath_image_reveals_answerfalse positives on area-model diagrams, and merged the two-pass Gemini vision usage so Pass-1 tokens are no longer dropped (#373). -
Observability & Monorepo — Request metadata now carries Langfuse
user_idandsession_idfor end-to-end tracing (#219), and the inceptbench.com website has moved into the monorepo underwebsite/for unified CI and deploys.
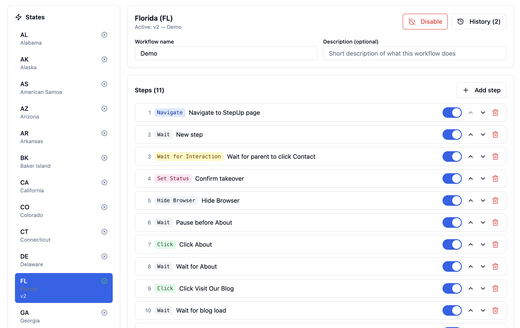
EduPaid v2.28.0: ESA Automation, Async Payments & Parent Platform
May 20, 2026 (v2.28.0) ships configurable ESA workflows and checkout automation, faster parent billing surfaces, async payment processing via outbox and Cloud Pub/Sub, and a parent portal migration—subscription portal, student dashboard, and purchase/checkout now read primary data from apps/core (NestJS) view endpoints instead of Supabase edge functions.
- Admin portal — configurable ESA automation workflows: Manage Florida and other state ESA browser automations without a code deploy from the ESA Workflows tab—edit steps in place (navigation, clicks, waits, handoffs), toggle steps and which states expose automation, save versioned definitions with publish-on-next-run behavior, and roll back when a portal UI change breaks a selector.
- Parent portal — start ESA automation from checkout: When automation is on for your state, ESA checkout offers Continue with automation after you pick the learning track; EduPaid passes student details into the secure browser flow, with manual funding below the divider. The automation path appears only where an active workflow exists for your state.
- Payments — async processing via Pub/Sub: Completed payments write results to the database and enqueue an outbox event; a relay publishes to Cloud Pub/Sub, and consumers process subscription updates, next-payment scheduling, and provider webhooks asynchronously. This decouples “payment succeeded” from downstream side effects (unlike the old tightly coupled pipeline) with idempotent consumers and retries, so one failing follow-up step no longer blocks or destabilizes the whole flow.
- Parent portal — core backend migration: The main parent experiences—subscription portal, student dashboard, and purchase/checkout—now load their primary data from apps/core (NestJS) view endpoints instead of Supabase edge functions, consolidating parent-facing logic in the centralized backend.
- Wallet top-up for defaulted subscriptions: Defaulted learning tracks now appear in the wallet top-up flow alongside active and scheduled enrollments so families can catch up without contacting support first—amount, payment method, and confirmation match the usual top-up experience.
- Faster subscription history: The Subscription history page opens sooner; balances, student-scoped activity, filters (all activity, upcoming, refunds, ESA and wallet deposits), and line-item details behave as before with less initial wait.
EduLLM-ELA: Inference-Time Verifier Hits 93.88% — +11.76pp Lift Now in Production
A multi-pass inference-time verifier with an escalating Haiku → Sonnet → Opus stack is now the production default for Grade-6 Language.
- +11.76pp lift, shipped to prod — Grade-6 Language jumped 82.13% → 93.88% on a 621-item ablation, at $0.01515 per question (66 q/$1) and 15.8s median latency.
- Single-epoch constraints SFT — null result — DS-R1-32B with constraints-augmented prompts at 1 epoch came in at 88.57% vs. 89.84% baseline. Rules out one-shot native rule learning; 3-epoch follow-up running.
- Bigger base alone doesn’t help — null result — Raw Qwen3-235B-A22B (no task-SFT) hit 88.06% on Grade-6 Language, below the 32B baseline. Task-specific fine-tuning is required regardless of base size.
EduLLM Science: 99%+ Agentic Coverage, SFT Progress
This week we expanded agentic improvements across grades under the latest InceptBench version, reaching 99%+ pass rates across eight of nine grades, with Grade 4 at 98.5%. We also advanced the SFT pipeline, achieving a 96.5% pass rate with a small training sample set while identifying generation latency and token volume as the next optimization targets.
- Agentic performance – Reached 99%+ pass rates across eight grades; Grade 4 is close behind at 98.5%.
- Interest support – Interest-conditioned generation currently tracks around 90%, and is a priority for continued improvement.
- SFT pipeline – Achieved a 96.5% pass rate with 10 training samples per request; next work focuses on reducing token usage and generation time.
EduLLM Social Studies: Agentic Completion & Costing Snapshot
EduLLM Social Studies reached 100% agentic completion for Articles across Grades 5-12. Cost and latency benchmarks show Gemma4-26B as the strongest quality-cost operating point among current evaluated options.
- Articles complete by agents (G5-12) – Agentic pipeline now covers Articles for Grades 5 through 12 at 100% completion.
- Best quality-cost operating point – Gemma4-26B: 96.8% CORE, ~5-6s p50 inference (estimated), 4xH200, and ~$3.70 per 1k questions.
- Higher-cost alternatives – Qwen3-32B: 96.7% CORE, 7.6s p50, 2xH100, ~$6.94/1k q; Qwen3-235B: 96.1% CORE, 8.5s, 4xH200, ~$55.56/1k q.
- Low-cost production baseline – Qwen3-14B (prod): 93.8% CORE, 6.6s p50, 1xH100, and ~$0.87 per 1k questions.
Athena Applets: Weekly Progress & Autonomous Fixes
6 lessons approved this week with a 55% approval rate. Total review time was 84.4 minutes (7.7 minutes per iteration), and the autonomous agent fixed 79% of feedback issues without manual intervention.
- Production output – 6 lessons approved this week (Grade 3: 5, Grade 3 TEKS: 1). No new lessons generated; all activity was iterating on existing lessons.
- Approval rate – 55% approval rate (6 approvals from 11 total iterations).
- Autonomous agent performance – 79% of fixes successfully resolved by autonomous agent (56 out of 71 feedback items), significantly reducing manual intervention time.
- Efficient iteration cycle – 11 total iterations completed in the past 7 days (5 feedback rounds, 6 approvals) with an average of 7.9 comments per lesson (55 total comments across 7 unique lessons).
- Multi-grade coverage – Current review queue: 132 lessons ready for validation (Grade 3: 24, Grade 4: 4, Grade 6: 60, Grade 7: 4, Grade 3 Supporting: 37, Grade 5 TEKS: 1, Grade 6 TEKS: 2).
- Review time insights – Average review time of 7.7 minutes per iteration (total 84.4 minutes).
- Complete lesson catalog – See the full list of all uploaded lessons across grades in this lesson catalog with direct links to each lesson.

Marauders Map: MFIPS Identity Upgrade & School-Hours Camera Scheduling
Marauder’s Map strengthens identity persistence with a new ReID backbone and three-gate fusion that cuts duplicate identity frames by 72%, and adds automatic school-hours scheduling so GPU workers only run when cameras are needed.
- MFIPS — OSNet-AIN + 3-Gate Fusion + Gallery Protection — OSNet-AIN replaced SBS R50-IBN as the ReID backbone after a three-model shootout, delivering tighter within-person clusters and wider between-person gaps. Every assignment must clear three hard gates: colour histogram match (> 0.30), majority feature agreement (≥ 2 of 3), and a confidence margin above the second-best candidate (> 0.06). Gallery centroids are now updated exclusively from high-confidence face-recognition matches (≥ 0.55), closing the EMA contamination loop — reducing duplicate identity frames by 72% (214 → 60) and achieving 99% coverage for Fran and 98% for Jenny with zero wrong-IDs.
-
School-Hours Camera Scheduling — The orchestrator now checks a configurable time window every 60 seconds and shuts down GPU workers outside school hours. Each school defines its operating window via
worker_start_time,worker_end_time, andschool_hours_tz; workers pre-warm 5 minutes before the start bell so models are ready on time. Weekends are suppressed automatically, the gate fails open on backend errors so cameras never go dark unexpectedly, and aworker_status_changedSSE event keeps the dashboard banner in sync in real time.
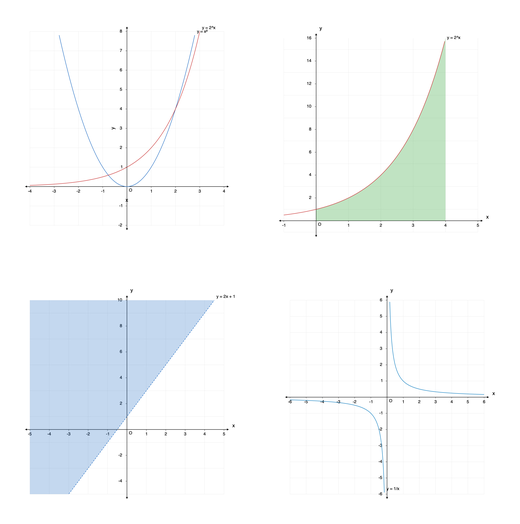
EduLLM SAT Math: 100% Pass Rate & Graph Generation Capability
SAT Math hits 100% pass rate on text-based (no image) questions across all three Digital SAT grades. Separately, we have built the capability to generate graph images — not yet used in benchmarks or production, but ready.
- 100% pass rate (text-based questions) – Achieved across Digital SAT, PSAT 8/9, and PSAT 10/NMSQT on questions with no images. 2 questions flagged for difficulty are false positives due to a curriculum definition gap being fixed.
- Graph image generation (capability built, not yet in use) – Generator can now produce graph images for questions that require them — multi-function plots, shaded regions under curves, linear inequality regions, and rational functions like y = 1/x.
Mosaic: Story-First AI Video Generation
Mosaic takes a single concept in plain language and builds a complete multi-scene animated video — screenplay, characters, scenes, and final export — through a guided 7-stage pipeline. Every stage is editable, every stage builds on the last, and the output is one cohesive MP4.
- Idea → Video in 7 stages — Describe your concept in natural language and walk through Idea, Research, Concept, Script, Assets, Scenes, and Builder. Each stage produces structured output that feeds into the next.
- Grounded research — The platform searches the web in real-time, finds relevant trends and data, and tags insights as Trend, Key Insight, or Direction with verifiable source URLs.
- Consistent visual assets — Characters, environments, and objects are extracted from the script and generated as multi-angle reference images, keeping appearance consistent across every clip.
- 6-panel storyboard previz — Before any video is generated, each clip gets a detailed scene breakdown with visual direction, dialogue, sound design, and a 6-panel storyboard preview.
- NLE-style Builder with AI Director — A full video editor with a timeline, continuous playback, and a chat-based AI assistant that can trim, split, regenerate, or create transitions using natural language.
Alpha Coach Analysis Platform: Alphi Quality, Analysis Accuracy & Monitoring
A strong week across the board — Alphi is sharper and faster, recorded-session grading is more accurate, and error monitoring now covers every sub-app.
- Alphi — Coaching Quality — Socratic discipline is tighter: Alphi auto-detects the student’s grade and adapts its language and examples to match, uses real-world analogies and mnemonics by default. The long-session latency drift from last week is also fixed — responses stay fast from the first turn to the last. Coaching identity rebuilt around joy and love of learning.
- Recorded-Session Analysis — Accuracy Gaps Closed — Four grading accuracy gaps closed using Whisper-validated ground truth. Analysis prompts now embed the Alpha School operating model and speaker map — calls are graded using Alpha’s own standards with clean speaker attribution.
- Error Monitoring — Sentry and Google Chat error alerts now cover all three sub-apps (web, realtime server, and desktop agent). One channel gets pings from all of them, throttled to avoid noise.
- Dashboard UI — Five shared UI components consolidated across the dashboard. Fixed a silent bug where sessions that failed to load appeared empty instead of showing an error.
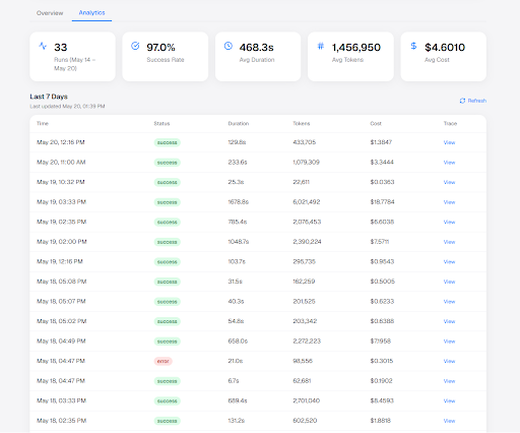
BrainTrust: New Features This Week
BrainTrust ships autonomous documentation updates, expanded reasoning model controls, and a new analytics dashboard for expert editors — giving teams deeper automation, more model flexibility, and better visibility into their work.
- Docate — Autonomous Documentation Agent – An autonomous agent that keeps BrainTrust documentation automatically up to date based on the main branch commit history is now live and connected to Synapse, so your docs stay in sync with your codebase without manual intervention.
- Reasoning Support for Models – Users can now set the reasoning effort level for all supported models in BrainTrust, giving teams full control over the depth of model reasoning and enabling better use of advanced model capabilities.
- Analytics Dashboard for Expert Editors – Expert editors can now track their expert invocations over the past 7 days with aggregate statistics, and drill into individual traces for each invocation — providing clear visibility into usage and performance.
- Agent Iterator (v1) – BrainTrust’s Agent Iterator is now live. It takes a user request, automatically updates the agent, and tests it end-to-end — iterating until the agent achieves the expected behaviour, so you spend less time on manual trial-and-error.
EduLLM Math: 99% across all grades
Agentic model has hit 99s on all grades.
- 99% pass rate: Pass rate for Math Grades 1-8 has improved to 99%+.
- SFT: SFT model for grade 4 hit a wall and regressed on the latest InceptBench version. Experiments on different models are ongoing.