
13 May, 2026 - Last week in TI
- Rahul Subramaniam
- Releases
- May 13, 2026
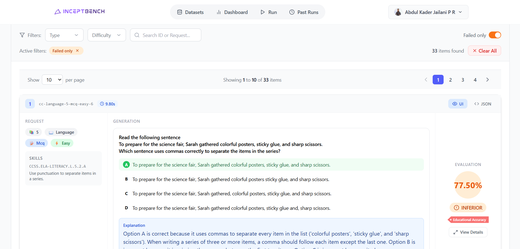
InceptBench: Evaluator v2.5.7, Curriculum v1.8.0 & Dashboard Polish
InceptBench shipped evaluator v2.5.7 with SAT Reading & Writing support and a standalone variety-check runner, paired with curriculum v1.8.0 with 16+ CCSS math fixes, and rolled out improvements per-message display conventions across the benchmark UI.
- Evaluator v2.5.7 Released — Added the SAT Reading & Writing evaluation overlay with subject-specific prompt layering for rubric alignment. Shipped a standalone variety-check runner that generator teams can invoke locally without running a full benchmark. Improved ELA question evaluation based on feedback from Academic teams.
- Curriculum v1.7.1 & v1.8.0 — 16 CCSS Grade 7 math fixes for difficulty definitions and supported formats, plus continued grade-naming standardization across CC and Athena-CC (K, 1, 2 … 12).
- Benchmark UX Improvements — Evaluator error messages now surface the real InceptBench failure reason instead of generic ’no evaluation items found.’ The Failed only toggle no longer shows pending items during active runs, failed dimensions are visible inline on each row without opening the detail modal, and the manual retry variety check option now works correctly.
- Automated PR Checks — Strengthened CI quality gates and Greptile review coverage for faster, more reliable code review.
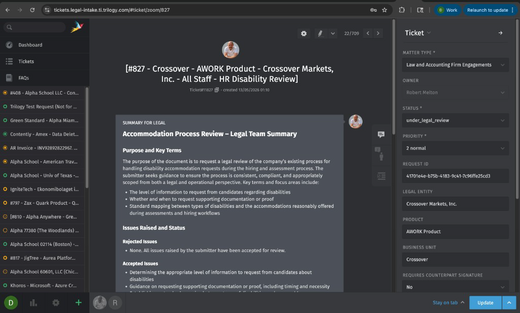
Legal Intake: Intelligent Notifications, Accurate Entity Sync & Automated Ticket Formatting
Legal Intake delivers smarter notifications that respect user preferences, accurate legal entity synchronization from CIMS, automated ticket title formatting, upgraded AI models, and API key management for programmatic access.
- Notification Management – Users receive only critical updates (ticket status, new submissions, comments), eliminating notification spam from routine actions like title changes and attorney assignments.
- Accurate Legal Entity Synchronization – CIMS entity sync displays correct entities at intake at the time of request.
- Automated Ticket Title Formatting – Auto-generates titles in the format requested by Joleen, eliminating manual data gathering and reducing human-prone errors.
- Enhanced AI Performance – Upgraded to latest Grok models for faster, more accurate document review and analysis.
- API Key Management – Users can now generate API keys for programmatic access; ticket creation via API ships this week.
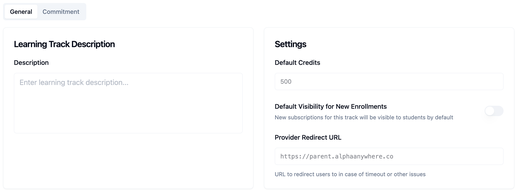
EduPaid v2.27.1: Visibility, Faster Students & Marketplace Listings
Adds default and bulk enrollment visibility plus a faster Students page; the new AlphaAnywhere Summer track is ESA-eligible and available on Step Up For Students (AlphaAnywhere has been notified—we expect ESA orders), and EduPaid is listed on Odyssey as vendor and product under the 2HourLearning name.
- Programs & marketplaces: The new AlphaAnywhere track for the Summer program is ESA-eligible; students can purchase it on the Step Up For Students ESA site. AlphaAnywhere has been notified and we are expecting ESA orders. - EduPaid is now listed on the Odyssey platform as both a vendor and a product under the 2HourLearning name.
- Default visibility for new enrollments and bulk family visibility: Choose how new subscriptions on a track start for parents and students—visible immediately or hidden until you opt them in—via Default visibility for new enrollments on the track. From the track detail page, Show for all students and Hide from all students update every current enrollment in one confirmation dialog instead of row-by-row edits.
- Faster Students list loading: The provider Students page loads roster and enrollments in smaller, parallel steps; in heavy real-world cases load time has improved from about 36 seconds to about ~6 seconds, with the same filters and exports as before—only the initial wait is shorter.
EduLLM Science: Agentic Recovery to 99%, SFT Next
After the newer InceptBench version and SME feedback reset prior milestones, pass rates briefly dropped to ~80%. This week we recovered Grade 1 to 99%, with smaller Grade 2 batches also showing 99% pending a full InceptBench run. We leaned more on autonomous improvement, intervening when contradictions, drift, or bloat stalled benchmark progress.
- Agentic recovery – Reclaimed 99% on Grade 1 after the benchmark reset; smaller Grade 2 batches are also tracking at 99%.
- SFT pipeline – Generated the new databank using the updated generators and will proceed toward training to reclaim SFT model performance.

EduLLM Social Studies: K–4 Agentic & Grade 6 SFT Expansion
Social Studies agentic mode now covers Kindergarten through Grade 4 at 95%+ pass rate, with a clear path to 99% by the end of the week. On SFT, we expanded to Grade 6 at 94% pass rate and are targeting 98% by the same milestone — building on the Grade 5 US History SFT work and evaluation discipline from prior releases.
- Agentic — K–4 – Added support for grades K–4 with 95%+ pass rate; driving toward 99% by end of week.
- SFT — Grade 6 – Expanded supervised fine-tuning coverage to Grade 6 at 94% pass rate; targeting 98% by end of week.
Athena Applets: Strong Quality Metrics & Multi-Grade Expansion
8 lessons approved this week with a 38% approval rate. Total review time was 114.1 minutes (5.4 minutes per iteration), and the current review queue holds 131 lessons.
- Production output – 8 lessons approved this week (all Grade 3 CCSS). No new lessons generated; all activity was iterating on existing lessons.
- Strong approval rate – 38% approval rate (8 approvals from 21 total iterations).
- Efficient iteration cycle – 21 total iterations completed in the past 7 days (13 feedback rounds, 8 approvals) with an average of 4.6 comments per lesson (60 total comments).
- Multi-grade coverage – Lessons approved in Grade 3 (8 lessons), with a review queue of 131 lessons ready for validation (Grade 3: 22, Grade 3 TEKS: 1, Grade 3 Supporting: 37, Grade 4: 4, Grade 5 TEKS: 1, Grade 6: 60, Grade 6 TEKS: 2, Grade 7: 4).
- Review time insights – Average review time of 5.4 minutes per iteration (total 114.1 minutes).
- Complete lesson catalog – See the full list of all uploaded lessons across grades in this lesson catalog with direct links to each lesson.
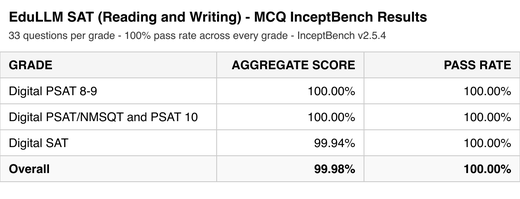
EduLLM SAT (Reading and Writing)
We regained 100% pass rate on the MCQ generator after the regression that occurred after evaluation changes on IB side, and restarted work on static articles to get them to 100% pass rate after the recent regression.
- After the evaluation changes on IB, the scores for the MCQs regressed to below 80% initially. We now have a pass rate of 100% on the latest evaluation setup across all grades.
- From the evaluation changes, there was also a regression in the static articles which we noticed a couple days back while working on articles with student interests. We’ve shifted focus from interest fields to getting score for this back to a 100. current scores are Articles - Currently at 91% for PSAT 10 and PSAT 8-9, SAT - 100%.
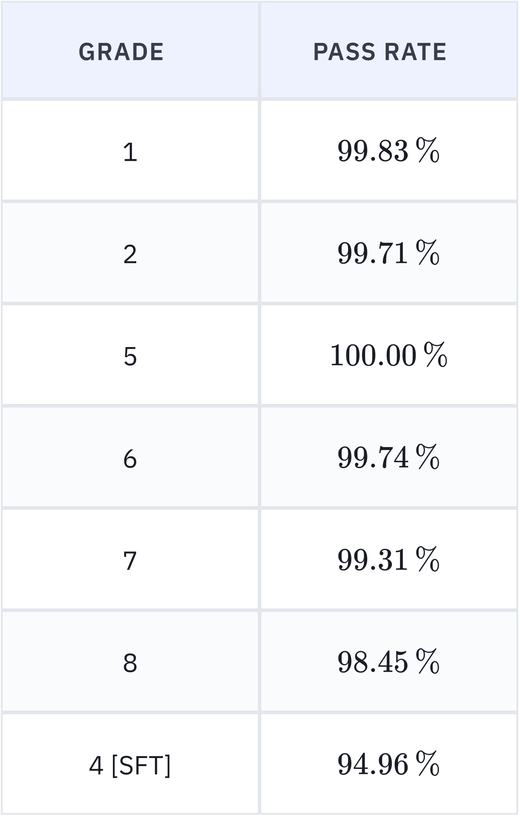
EduLLM Math: Improved pass rates and SFT model
Agentic model has hit 99s on all grades except grade 8. SFT model for grade 4 improved to reach 94%.
- Improved pass rates: Pass rate for Math Grades 1-7 has improved to 99+%.
- SFT: SFT model for grade 4 hit 94.96% pass rate.
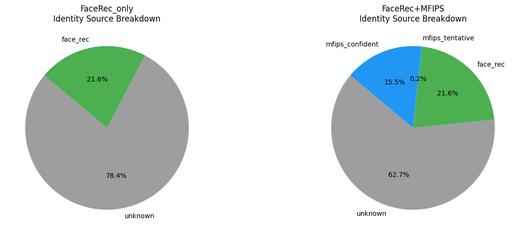
Marauders Map: Smarter Identity & Safety from Camera Feeds
Two new ML capabilities extend what Marauder’s Map can extract from existing CCTV feeds — persistent identity even when faces aren’t visible, and automated incident detection with classification and severity.
- Multi-Factor Identity Persistence (MFIPS) — Face recognition only works when a person faces the camera, which is a minority of the time in a school. MFIPS adds a ReID fallback (SBS R50-IBN) that learns each person’s body appearance from face-recognized frames and matches them by body when their face is hidden — increasing identity coverage by 73% (unknowns drop from 78.4% → 62.7%) with zero additional hardware. Face recognition remains the highest-trust signal and is never overridden.
- Incident Detection as a Spatial Signal — Gemini 2.5 Flash’s native video understanding detects and classifies safety incidents (bullying, fights, verbal altercations, harassment) with severity levels directly from video — no lossy frame extraction. Evaluation achieved 83% accuracy with 100% precision (zero false alarms), and at $52/month for 1K clips/day it is 5× cheaper than Claude and cheaper than a dedicated GPU, making it viable as a continuous signal across every camera.
Alpha Coach Analysis Platform: Guide Insights Approved, Alphi & AI Queue Monitoring
Guide Insights hit a milestone — the final coaching feedback format for guides got sign-off from Andy. Alphi got a stronger coaching identity, and the ingestion queue is now monitored by an AI agent that handles issues automatically.
- Guide Insights — Format Approved — The final structure of the AI-generated coaching feedback email for guides has been approved. The email adapts to each session — a student engagement section is included only when there are significant problems affecting learning, and omitted otherwise. Keeps feedback focused and relevant every time.
- Alphi Live Coach — Alphi now has a stronger coaching identity with a tighter Socratic rule — guiding students to figure things out themselves rather than handing over answers. We’ve also identified and are fixing a latency issue where response times drift up in longer sessions.
- AI-Powered Queue Monitoring — A Claude Code agent now watches the ingestion queue around the clock. When it detects a problem it diagnoses and resolves it automatically. If it encounters a case it hasn’t seen before, it flags it to the team — no human needs to watch the queue, only act on the genuinely new stuff.
EduLLM SAT Math: Scores Impacted by Difficulty Integrity Checks
New difficulty integrity checks introduced in InceptBench have reduced pass rates to the 85–90% range across grades. We have added tool support to address math accuracy issues, updated the curriculum for the new difficulty definitions, and are working on a new architecture to structurally resolve the remaining gap.
- Score update – Pass rates are now in the 85–90% range following the new difficulty integrity checks — same pattern seen across other SAT generators this week.
- Tools support – Added tool-calling support to help the generator with math accuracy issues.
- Curriculum update – Updated the SAT Math curriculum to align with the new difficulty integrity definitions.
BrainTrust: Upcoming
Powerful new capabilities are coming soon to BrainTrust, further reducing the need for manual intervention in agent development, debugging, and documentation. The Agent Iteration System goes live this week; the Debugger Agent and Documentation Auto-Update Agent are on the way.
- Agent Iteration System (v1) – Slightly delayed but going live this week: autonomous agent iteration and testing without any human involvement, enabling agents to self-improve and validate continuously.
- Debugger Agent – A dedicated agent that automatically identifies and traces issues in BrainTrust agent executions, making it faster to diagnose and resolve problems.
- Documentation Auto-Update Agent – An agent that monitors code changes across any connected codebase and automatically updates relevant documentation, keeping docs perpetually in sync.