
6 May, 2026 - Last week in TI
- Rahul Subramaniam
- Releases
- May 6, 2026
Legal Intake: Zammad Integration Reliability & Streamlined Invoice Processing
Legal Intake strengthens Zammad integration reliability and streamlines invoice processing — eliminating session timeouts, fixing notifications, automating ticket titles, and deploying production observability.
- Zammad Desktop App Support – Enabled ticket-sharing for beta desktop app, eliminating session timeout issues.
- Fixed Email Notifications – All users now reliably receive email updates on ticket activity.
-
Deterministic Ticket Titles – Automated
<Ticket Number>-<BU>-<Product>format eliminates manual title editing by attorneys and reduces invoice reallocation errors for finance. - Zero-Downtime CDK Deployment – Updated Zammad infrastructure with zero service interruption.
- Production Observability – Full CloudWatch integration: Docker logs, EC2 host logs, host metrics via CloudWatch Agent, container metrics via systemd service.
- Adoption Milestone – 36 tickets in 9 days since launch.
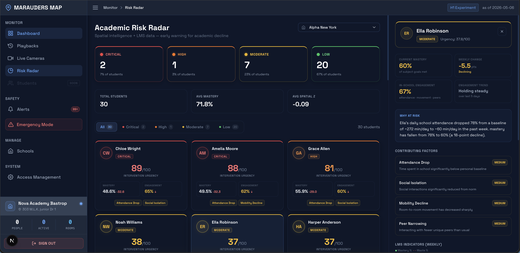
Marauders Map: Product BrainLift & Academic Risk Radar (H1)
Marauders Map now has a validated product thesis and its first learning-outcomes feature — a guide-facing Academic Risk Radar that fuses spatial behavior with LMS mastery data to flag students at risk before grades reflect it.
- Product-Focused BrainLift v2 — Rebuilt the product document around six stakeholder-endorsed beliefs, a concrete LMS data contract (fields, cadence, join-key, 90-day window), and a gated hypothesis program where H1 (spatial deviation predicts academic decline) must validate at ≥35% precision before any Phase 2 investment proceeds. Includes honest per-belief validation status and explicit anti-goals (not surveillance, not discipline, not guide-replacement).
- Academic Risk Radar — H1 Implementation — Full-stack feature fusing 12 weeks of per-student spatial signals (attendance, room transitions, peer interactions, unique peers) with weekly LMS mastery scores into a single risk dashboard. Each student gets a 0–100 Intervention Urgency score with differentiated contributing factors — including Social Isolation and Peer Narrowing that only spatial tracking can detect — a plain-English narrative, and evidence charts split into LMS Indicators vs. Spatial Signals, giving guides instant rationale to act.
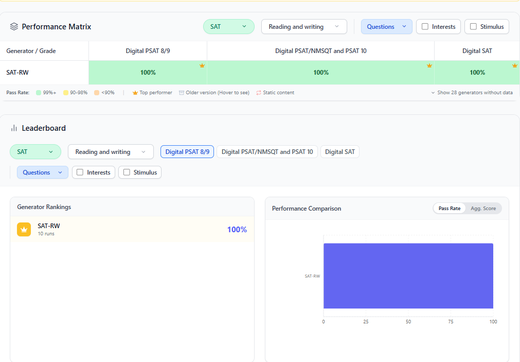
EduLLM SAT (Reading and Writing): MCQ Generator Live on InceptBench
This week we deployed the MCQ generator to production, hit 100% pass rate across all three SAT R&W grades on InceptBench, and contributed a subject-specific evaluation layer to InceptBench for SAT Reading and Writing.
- 100% Pass Rate on MCQs – Deployed the MCQ generator and ran InceptBench evaluations across all three grades: Digital SAT: 99.9%, Digital PSAT 8/9: 100.0%, Digital PSAT/NMSQT and PSAT 10: 99.7%, all at 100% pass rate.
- SAT R&W Evaluation Layer in InceptBench – While benchmarking, we identified gaps between the general pedagogy evaluation and the specific requirements of SAT Reading and Writing items (stimulus field structure, substandard-specific distractor rules, difficulty calibration). This prompted the creation of a dedicated SAT R&W evaluation overlay in InceptBench (PR #370), now live in v2.5.5.

EduLLM Social Studies: Incept-Social-SFT on Grade 5 US History (1491–1850)
We ran Incept-Social-SFT — Mistral 24B fine-tuned on a 75k-example base dataset whose atom-grounded thinking traces were generated by Haiku — on Common Core / Grade 5 Social Studies — US History (1491–1850) with the Questions category (360 items). Quality stayed very strong — 99.4% aggregate score and 97.7% pass rate across 360 evaluated items — while variety scored 3/10, signaling we should diversify prompts and stems in the next iteration. Five items failed generation (355 / 360 generated); evaluation covered 100% with no evaluation errors. The full run took 34m 50s at ~13.9s average generation latency.
- SFT stack – Mistral 24B on a 75k base dataset with atom-grounded thinking traces from Haiku.
- Run scope – Incept-Social-SFT, CC curriculum, Questions, 5th Grade US History (1491–1850), Social Studies.
- Coverage & errors – 360 total items; generation 99% (355 / 360); 5 generation failures and 0 evaluation failures (360 / 360 evaluated).
- Quality – 99.4% aggregate score and 97.7% pass rate on all evaluated items.
- Variety – 3 / 10 variety score — accuracy is high; improving lexical and scenario diversity is the next focus.
- Performance – 34m 50s wall time, 13.93s average generation latency (run created May 6, 2026).

EduLLM-ELA: Accuracy & Cost Benchmarks
EduLLM-ELA now has two validated operating points balancing accuracy, latency, and cost — with active training data work underway to push both metrics further.
- High-accuracy tier — 98% accuracy at 20-second latency, costing 30 questions per dollar.
- High-efficiency tier — 93% accuracy at 10-second latency, costing 50 questions per dollar.
- Training data improvements — Actively cleaning training data based on user feedback and augmenting the dataset to 125 examples per request to improve both tiers.
Athena Applets: Strong Quality Metrics & Multi-Grade Expansion
10 lessons approved this week with a 50% approval rate. Total review time was 126 minutes (7.0 minutes per iteration), and the current review queue holds 147 lessons.
- Production output – 10 lessons approved this week (all Grade 3 CCSS). No new lessons generated; all activity was iterating on existing lessons.
- Strong approval rate – 50% approval rate (9 approvals from 18 total iterations).
- Efficient iteration cycle – 18 total iterations completed in the past 7 days (9 feedback rounds, 9 approvals) with an average of 1.8 comments per lesson (32 total comments).
- Multi-grade coverage – Lessons approved in Grade 3 (10 lessons), with a review queue of 147 lessons ready for validation (Grade 3: 39, Grade 3 Supporting: 37, Grade 4: 4, Grade 5 TEKS: 1, Grade 6: 60, Grade 6 TEKS: 2, Grade 7: 4).
- Review time insights – Average review time of 7.0 minutes per iteration (total 126 minutes).
- Complete lesson catalog – See the full list of all uploaded lessons across grades in this lesson catalog with direct links to each lesson.
EduLLM Science: SFT at 98.4+, Agentic Progress Continues
SFT performance has finally moved beyond the long-standing 95–98% window and is now at 98.4%+, steadily moving toward 99%. Agentic mode also improved this week with an incremental ~1% pass-rate gain, though it has not yet reached the 99% target.
- SFT breakthrough – Broke through the 95–98% plateau and reached 98.4%+, continuing toward 99%.
- Agentic gains – Pass percentage improved by roughly 1% week over week, with 99% still the next milestone.
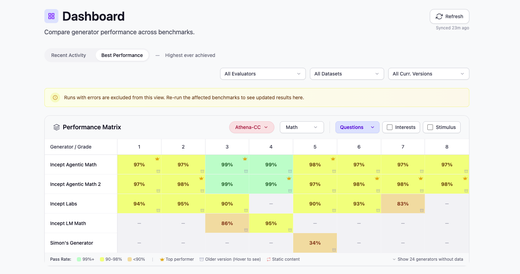
InceptBench: Curriculum v1.7.0 & Evaluator v2.5.4 Released
InceptBench releases major updates including standardized curriculum naming across CC and Athena-CC, enhanced evaluation pipeline, and database consistency improvements for the benchmark dashboard.
- Incept Curriculum v1.7.0 – Standardized grade naming across CC and Athena-CC curricula with simple numeric identifiers (K, 1, 2 … 12), replacing inconsistent formats like ‘1st Grade’, ‘CK Grade 1 Math’, and ‘Kindergarten’. Added CC/Social Studies curriculum for Grades K to 4.
- Enhanced Evaluation Pipeline – Resolved answer leakage issues from questions, improved image evaluation quality, and fixed the broken audio evaluation pipeline for more reliable multi-modal content assessment.
- Stricter Stimulus Validation – Implemented stricter checks for stimulus presence (image, audio, video) and fixed markdown table recognition as valid stimulus, addressing evaluation accuracy concerns from partner studios.
- Improved Content Evaluation – Moved ‘Interest check’ to the important tier for better content quality assessment, and enhanced article decomposition and evaluation processes for more thorough content analysis.
- Database Migration – Ran Supabase migration to ensure consistent naming conventions across the benchmark dashboard, improving data integrity and user experience.
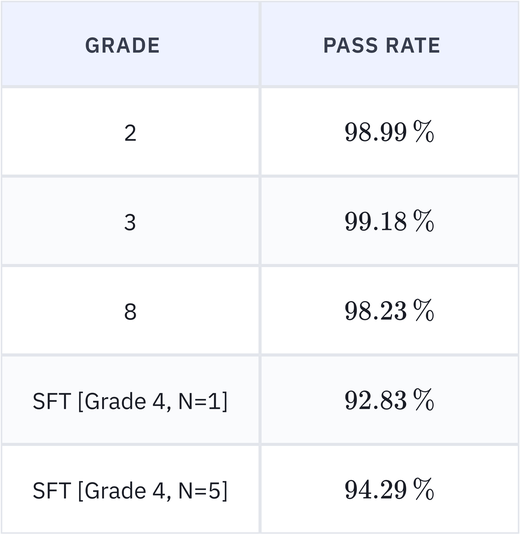
EduLLM Math: Improved pass rates and SFT model
EduLLM Math has improved pass rates for Math Grades 2, 3 & 8, and got a improved pass rates on SFT model for grade 4.
- Improved pass rates: Pass rate for Math Grades 2, 3 & 8 has improved to 98.99%, 99.18% and 98.23%.
- SFT: SFT model for grade 4 hit 92.83% pass rate with N = 1 and 94.29% pass rate with N = 5.
BrainTrust: Sherlock Researcher
BrainTrust gains a powerful new research expert that delivers deep, verified research reports without leaving the platform.
- Sherlock Researcher — A new BrainTrust expert purpose-built for deep research. It leverages Gemini Deep Research under the hood via MCP Hive, independently extracts and verifies claims from research output, and delivers cited, fact-checked research reports — all within the BrainTrust interface.
- Coming Next: Auto Agent Iteration — V1 of a system that automatically iterates on and improves agents without any manual effort from the user — taking the human out of the loop.
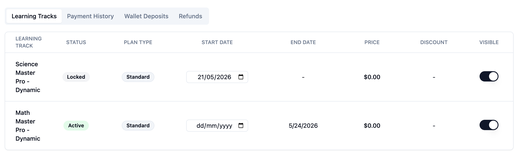
EduPaid v2.27.0: Enrollment Start Dates, Visibility & Parent Plan Selection
Providers set each learner’s billing start date on the subscription and control when enrollments appear to families—so setup can finish before parents see charges or track details. Parents get a dedicated plan-selection step when multiple payment options exist, with clearer checkout and prompts to add a payment method when needed so pricing stays accurate.
- Provider portal — enrollment start date and visibility: Set billing start on the subscription (future dates schedule the first charge that day; EduPaid uses this field instead of external roster metadata). Toggle visibility so learning tracks stay hidden from parent and student portals until you are ready; existing enrollments keep current visibility and new ones stay hidden until you turn visibility on.
- Parent portal — plan selection before checkout: When a track offers more than one way to pay (for example standard versus commitment), parents choose on a dedicated plan-selection step with clearer cards, then enter checkout when ready. If a payment method is required before plans load, the flow prompts to add a card first; checkout layout, order summary, and discount handling were refreshed so totals and cadence are easier to follow.
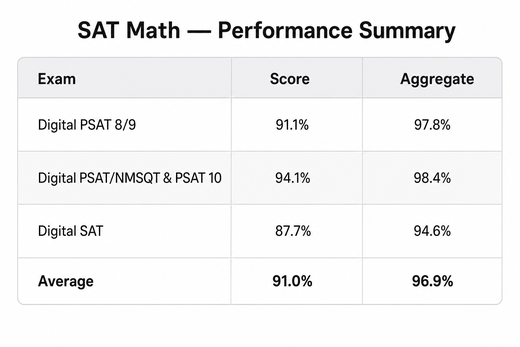
EduLLM SAT Math: InceptBench Results & Generator Improvements
EduLLM SAT Math has run InceptBench across all three Digital SAT grades and added support for question variety, fractional/decimal/negative answers, and image-aware questions.
- InceptBench results: Digital PSAT 8/9: 91.1% pass rate (97.8% aggregate). Digital PSAT/NMSQT and PSAT 10: 94.1% pass (98.4% aggregate). Digital SAT: 87.7% pass (94.6% aggregate).
- Question variety: Added support for variety across question types and difficulty levels.
- Numeric answers: Supports answers in fractions, decimals, and negative values.
- Questions with images: Generator produces image descriptions in the question; image generation support is not added yet.
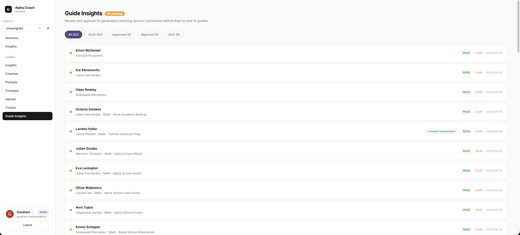
Alpha Coach Analysis Platform: Guide Insights, Faster Analysis & Self-Healing Queue
This week we shipped Guide Insights, made the ingest queue self-healing — 32 stuck sessions auto-recovered since the fix went live — and coaches now get notified the moment a recording can’t be accessed.
- Guide Insights — Guides now get an AI-generated email after each session with an Action Snapshot: student blocker, recommended strategies, practice focus, and follow-up. Guides can also see exactly how the AI coach worked with the student, so they stay aligned and can reinforce the same approach in the next session.
- Self-Healing Queue — 127 sessions were stuck and never completing. The queue now auto-recovers every 15 minutes — 32 sessions resolved without manual intervention since launch.
- Coach Drive Alerts — Coaches get an email the moment their recording can’t be accessed, telling them exactly what to fix. No more silent failures.
- Dashboard Fixes — 7 data inconsistencies fixed; 135 sessions that appeared ungraded now show correct PASS/FAIL results.