
15 April, 2026 - Last week in TI
- Rahul Subramaniam
- Releases
- April 15, 2026
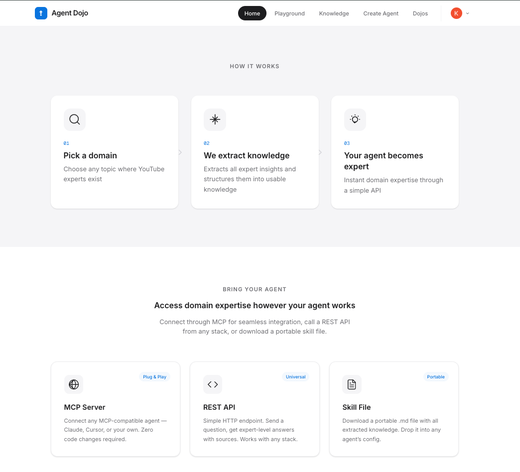
Agent Dojo: Expert Knowledge for AI Agents
Agent Dojo provides practitioner-grade expert knowledge to AI coding agents via MCP and REST APIs, helping them make better architectural decisions grounded in real production experience.
- Dojo Web App – Create, manage, and query dojos from the web interface. Each dojo ingests domain knowledge (YouTube, docs) and builds a Knowledge base for structured retrieval across multi dimensions.
- Add a Dojo – Spin up a new domain-specific dojo directly from the UI — pick a topic, provide sources, and it auto-builds the knowledge base. No CLI or manual pipeline needed.
- OpenCode + Dojo Experiment – Tested Dojo with OpenCode (open-source coding agent) on 5 real production scenarios across PostgreSQL, K8s, Redis, DynamoDB. Dojo won 3, tied 2, lost 0 — strongest on problems where the textbook answer has a hidden failure mode.
- Cursor Cloud Agent Skill Improvement – Used Dojo to improve Cursor Cloud Agent skills (ab-cursor-dev-setup). Tested improved skills on 3 real issues — 1 tie, 2 where improved skills produced measurably better output.
EduLLM Science: High 90s Quality with Image & Stimulus Support
EduLLM Science now generates K-8 science questions, with best score of 99% quality on grades 3 and 8, with grades 1 and 2 close behind at 96–97%. The rollout adds native image support via Gemini Pro and stimulus-based question generation, pushing accuracy well past the mid-90s baseline.
- InceptBench Scores – Benchmark testing achieved best score of 99% on grades 3 and 8, with grades 1 and 2 reaching 96–97%. More frequent runs will establish the score with higher confidence as we make further improvements.
- Image Support via Gemini Pro – Science questions can now include images, enabling richer, standards-aligned content — a key driver of the grade 3 improvement from mid-90s to 99%.
- Stimulus Input – Pass in a stimulus (diagram, passage) and the generator produces questions grounded in that context, supporting more authentic assessments.
Athena Applets: Strong Quality Metrics & Multi-Grade Expansion
5 new lessons generated, 1 lesson approved this week. Total review time was 29 minutes (9.7 minutes per iteration), and the current review queue holds 184 lessons.
- Production output – 5 new lessons generated and 1 lesson approved this week.
- Efficient iteration cycle – 3 total iterations completed in the past 7 days (2 feedback rounds, 1 approval) with an average of 0 comments per lesson (0 total comments).
- Multi-grade coverage – Lessons approved in Grade 3 (1 lesson), with a review queue of 184 lessons ready for validation (Grade 3: 74, Grade 3 Supporting: 38, Grade 4: 4, Grade 4 TEKS: 1, Grade 5 TEKS: 1, Grade 6: 60, Grade 6 TEKS: 2, Grade 7: 4).
- New lessons by grade – Grade 3 Supporting: 5 lessons.
- Review time insights – Average review time of 9.7 minutes per iteration (total 29 minutes).
- Complete lesson catalog – See the full list of all uploaded lessons across grades in this lesson catalog with direct links to each lesson.
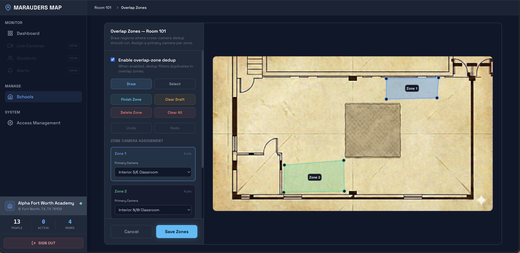
Marauders Map: Tracking Stability, Cross-Camera Dedup & RBAC Email Notifications
Marauders Map upgrades its tracking backbone to BoT-SORT with OSNet ReID for dramatically fewer ID switches, introduces overlap-zone-based deduplication to eliminate ghost duplicates in multi-camera rooms, and integrates AWS SES for automated RBAC lifecycle emails — invite, approve, reject, suspend, and restore.
- Tracking Stability via BoT-SORT ReID — Replaced motion-only Hungarian matching with BoT-SORT + OSNet appearance embeddings. ReID recovers associations through occlusions and a capped track buffer prevents stale-track buildup at ~1 Hz SAM3 cadence — fewer ID switches, longer track lifetimes, and cleaner floorplan trajectories.
- Duplicate Elimination via Overlap Zones — Admins draw overlap polygons on the floorplan and assign a primary camera per zone. The backend suppresses unrecognised duplicate tracks from secondary cameras while preserving face-ID’d people from either camera. A frontend filter further drops unrecognised markers when a recognised identity is already present in the zone.
- AWS SES Integration for RBAC Notifications — Automated lifecycle emails (invite, approve, reject, suspend, restore) via AWS SES with Jinja2 HTML templates. Admins get instant alerts on new sign-ups; pending users see status on each login attempt. Smart guards skip delivery to suspended accounts, and a dev-recipient whitelist enables safe non-production testing.
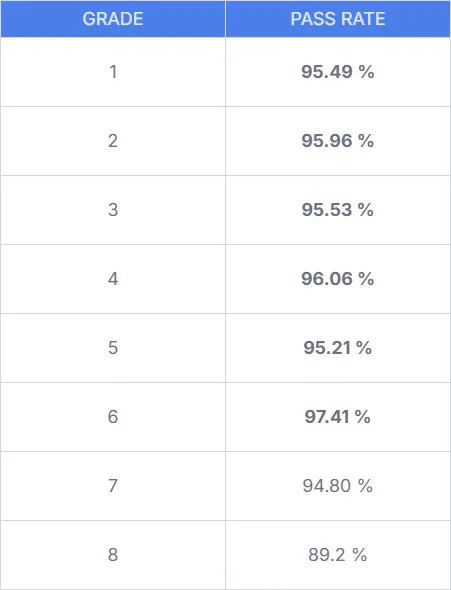
EduLLM Math: Improved pass rates & support for Math Grades 7 & 8
EduLLM Math has improved pass rates and added support for Math Grades 7 & 8.
- Improved pass rates: Pass rate for Math Grades 1, 2, 3, 4, 5, 6 has improved to cross the 95% mark.
- Support for Math Grades 7 & 8: Added support for Math Grades 7 & 8 standards, enabling generation of questions for these grade levels. Currently scoring 94% and 89% on the benchmark respectively.
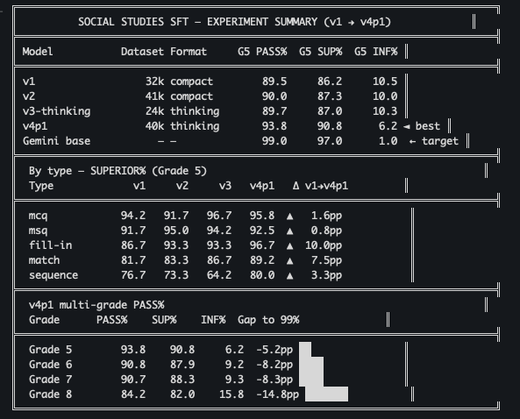
EduLLM Social Studies: Supervised Fine-Tuning Experiment (v1 -> v4p1)
We ran a 4-version supervised fine-tuning experiment for Social Studies and moved Grade 5 pass rate from 89.5% (v1) to 93.8% (v4p1), with stronger support scores and lower inference failures. The latest model sets a new internal best while establishing a clear path toward the 99% benchmark target.
- Best model so far (v4p1) – Grade 5 PASS improved to 93.8% (from 89.5% in v1), SUP rose to 90.8% (from 86.2%), and INF dropped to 6.2% (from 10.5%) for a net quality gain across the full evaluation stack.
- Question-type improvements – v4p1 outperformed v1 on every tracked type: fill-in +10.0pp, match +7.5pp, sequence +3.3pp, mcq +1.6pp, and msq +0.8pp, showing broad rather than narrow improvement.
- Multi-grade validation – v4p1 currently scores PASS rates of 90.8% (G6), 90.7% (G7), and 84.2% (G8), with remaining gap to the 99% target at -8.2pp, -8.3pp, and -14.8pp respectively.
- Experiment direction – Compact and thinking-data variants were both tested, and the current best result came from the 40k thinking setup, which will be used as the baseline for the next optimization cycle.
EduPaid v2.25.0: Wallet Receipts, TimeBack Apps & Provider API
Parents can download wallet top-up receipts from the success screen and subscription history; providers get a new Apps section for TimeBack learning app registration and connection, a cleaner Manual Discounts view with pagination and full CSV export, and a public provider API for programmatic transaction rescheduling with richer billing data.
- Download receipts for wallet top-ups: After a wallet top-up, parents can download a receipt from the confirmation screen; completed cash deposits in subscription history also include a download option on desktop and mobile, with clear feedback when a receipt is not yet available.
-
TimeBack apps, manual discounts & provider API: Register or connect a TimeBack learning app from the new Apps section (with an admin approval flow); the Manual Discounts tab excludes sibling discounts and adds server-side pagination and reliable paged CSV export; providers can reschedule transactions using their API key (no portal session), and
get-student-billingnow returnstransaction_idon each record for reconciliation.
BrainTrust: Finance Agent, Custom Models & More
BrainTrust continues to expand its capabilities this week — bringing powerful accounts payable intelligence via the Finance Agent and giving users direct control over the AI models powering their experts.
- A/P Account Reconciliation – The Finance Agent can now fully reconcile Accounts Payable accounts, aging vendors into time buckets so teams can instantly see what’s current, overdue, and by how much.
- Group-Level Consolidation – Run analyses across all subsidiaries in one go, giving finance teams a consolidated, bird’s-eye view of the entire group’s payables position without stitching reports together manually.
- Prepaid Account Analyses (In Progress) – Upcoming support for prepaid account verification: the agent will cross-check balances against amortisation schedules to surface discrepancies between what should have been paid and what was actually paid.
- Intercompany Drill-Downs with Multi-Currency Support (In Progress) – Improving intercompany account drill-downs to correctly handle entities that operate in different base currencies, ensuring accurate cross-entity reconciliation.
- Custom Model per Expert – Users can now select and configure the AI model powering their expert, enabling deeper personalisation and fine-tuned performance for each use case.
EduLLM ELA: Age-Appropriate Language Across K-12
Every generated question now uses vocabulary, sentence structure, and reading complexity matched to the target grade — ensuring assessments measure what they’re supposed to, not whether a student can decode language above their level.
- Grade-matched language – A 1st grader sees simple words and short sentences; a 12th grader gets nuanced, challenging language. Every question meets the student where they are.
- Why it matters – A question testing the right standard but written above a student’s reading level measures decoding, not comprehension. Age-appropriate language means fairer, more accurate assessments and fewer false negatives across every grade.